It’s a fancy auto-complete machine…
No matter which way you put it, LLMs are simply an auto-complete machine. That’s it. For example, complete the sentence:
The sky is...
Most people would say “blue.” This has been our childhood programming. Something we have used, learned, and heard again and again. LLMs are the same way. To get slightly technical, the LLM will ask itself, given all the previous words (“The sky is”), what word is most likely to come next? There would be a distribution of probabilities, and the highest one is chosen.
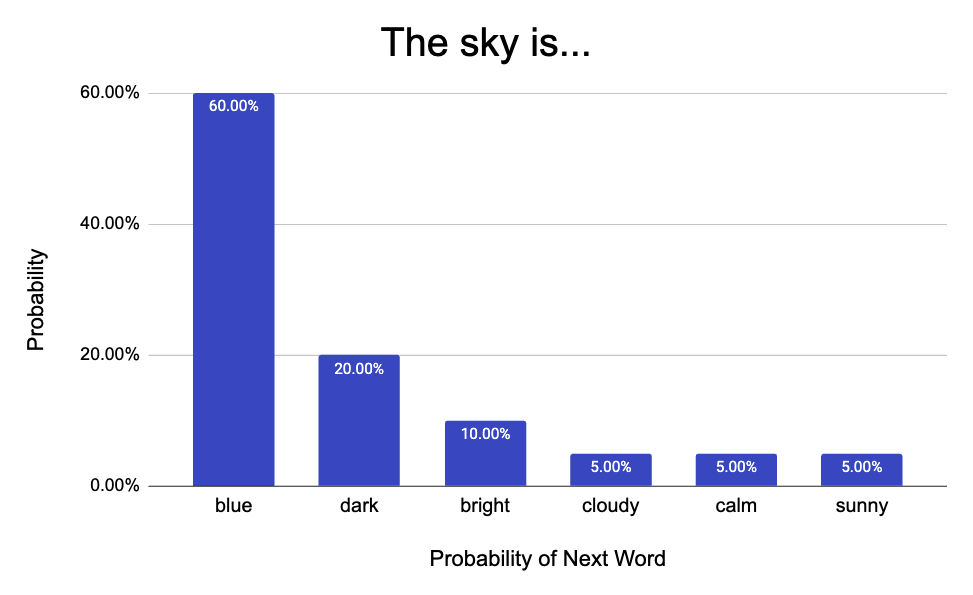
The model outputs “blue” because based on the dataset it has seen, blue is the most frequent. Much like the example above, LLMs are trained on vast databases about everything. Websites, books, research articles, and any resource a company can get their hands on. Therefore, if I ask the question:
Who was the 7th person to visit the moon?
You would struggle, because you weren’t “trained” on this knowledge. Though, the LLM responds with excitement “David Randolph Scott” (One word is generated at a time). Under the hood, the LLM asks itself, given the previous words, what is MOST LIKELY to be next. “David” has the highest probability. Then the auto-correct would continue. Given “Who was the 7th person to visit the moon? David”, what is the next most likely word? It would pick “Randolph”.
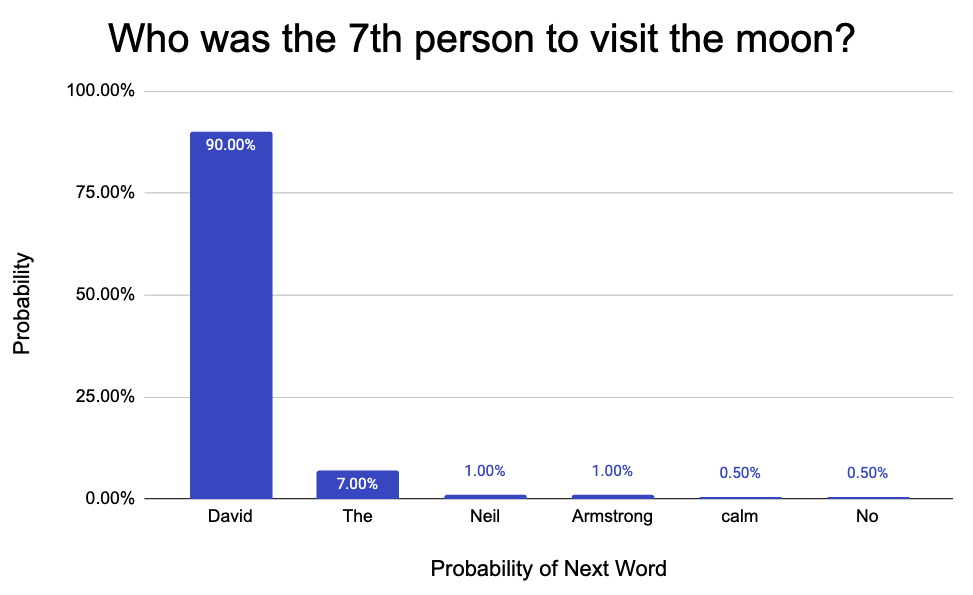
Every single piece of text that is generated comes down to a distribution like the one above. Notice it’s a “distribution.” This means the right answer is never guaranteed, but the word with the highest probability is. The underlying implication of this is that production use-case for LLMs should be carefully considered (more details in Hallucinations).