What is RAG?
In traditional AI approaches, a model is constantly trained and fine-tuned to stay up to date. LLMs are different, because the training process is generalized to many different texts (hence “Large” Language Models). This generalization means constantly re-training the model is cumbersome and expensive.
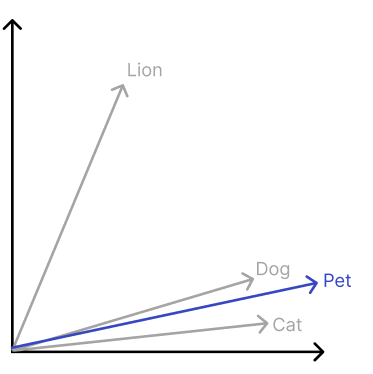
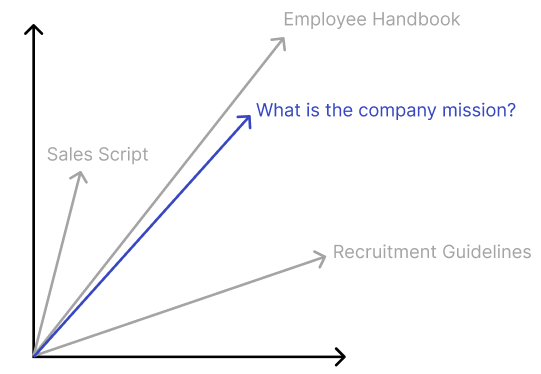
To mitigate this, Retrieval Augmented Generation (RAG) was created. RAG is the process of using new data to guide the LLMs. Rather than changing model parameters, your data is fed into the prompt as context. Explained in diagram form:

Notice how the LLM is not “trained” on your documents, rather given the “context” of it in the prompt. The model uses the document as a reference to answer the question. The process is very similar to a human. The human will have a question, look at the source, find the correct section, and then get the answer. Simple enough?